
Lessons Learned: Automated Script for Populating Meeting Handouts Database
A few years back, I developed a script for processing sets of PDFs to populate a database. That database is then used to dynamically generate the corresponding meeting handouts page for visitors to download the PDFs. The project was planned out so that pretty much everything needed for the meeting handouts page could be found in the set of PDFs. The only other extra thing I needed to do, besides making occasional minor corrections to the database, was store these handouts in a folder that was named with the meeting date, which I was already doing. Then I just needed to upload the files to the server and run the script.
Background
Prior to building the script, I was hard coding all the meeting pages. The typical process involved duplicating an existing meeting page and updating the meeting date. Then I took all the PDFs from the meeting, renamed them (as needed), and saved them to a folder created for that meeting. Then I created a ZIP file containing all the PDFs for that meeting, so visitors had the option to download all the files at once. Then I manually created all the HTML links for the meeting files and uploaded everything to the server. Once uploaded, I then needed to update a few different spots on the website so that they linked to the new meeting page.
Well, I was able to automate most of that process by updating the website so the meeting pages dynamically built themselves based off information stored in a database. I also developed a script for populating that database whenever a new set of meeting handout PDFs were forwarded to me.
Handout Information
To get all the necessary information about the handouts, the automation script was written to cycle through the PDFs using the DirectoryIterator class that's built into PHP. I asked the person who supplied the meeting files to name the PDFs so that they matched the link text they wanted to use. For example, to get the link text to say "Work Plan Status Report", the corresponding PDF needed to be named "work_plan_status_report.pdf".
From there, the script extracted the link text from the file name, replaced the underscores with spaces, and capitalized the first letter of each word using the ucwords() function.
In hindsight, it might have been better to ask for files that were named using title case (e.g. "Work_Plan_Status_Report.pdf"). Primarily because there were occasions where the link text contained acronyms and the ucwords() function isn't designed to handle those. Of course, I may have had other issues with title case since that can be tricky to do it properly. Especially since the style guides don't all agree on certain words being capitalized (or not).
The script also employed getSize() method available through the DirectoryIterator class to calculate the size of the file in kilobytes, which is displayed next to the link so visitors know how large the file is before they start downloading it. The script then stores the file name, file type (e.g. PDF), file size, and link text in the database.
The website would then read the handout information from the database and display a link like the one shown in Figure 1.
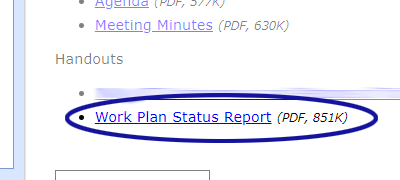
Figure 1. Meeting Handout Link
Meeting Information
One thing I still did manually was create the folder where the meeting handouts were stored. Every meeting, which were held monthly, had its own folder of handouts. The folder was named with the date formatted as "YYYYMMDD". After uploading that folder (and handouts) to the server, I passed the folder name to the automation script to run its processes. One process took that folder name (e.g. 20191001) and saved the value formatted as a SQL date field (e.g. 2019-10-01) to the database.
Based off that one field, the website could dynamically populate the necessary pages. If this was the first meeting of the year, a new year entry appeared on the page (see Figure 2).

Figure 2. Year Selection Page
After choosing a year, visitors are presented with a page with all the meeting dates for that year. The formatted date fields are used for populating that page (see Figure 3).
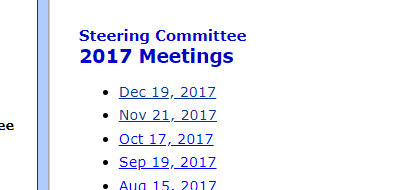
Figure 3. Meeting Date Selection Page
ZIP File
The other main thing I added to the script is for it to automatically create the ZIP file for me using the ZipArchive class that's built into PHP. Once created the script stored the necessary file information (e.g. file size, name, etc.) in the database. The page for displaying the meeting handouts then takes this information to dynamically display a graphic for downloading the ZIP file (see Figure 4).
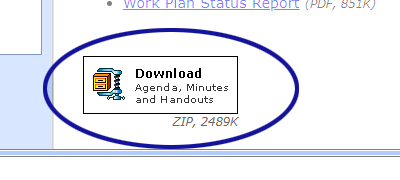
Figure 4. ZIP File Option
Final Thoughts
Besides the automation part, the best thing about the setup used in this project is that the resulting web pages are populated almost instantly. There's no need to worry about someone stumbling across a page that's not complete because I'm still manually creating the individual database entries. The script does everything in usually less than a second.
Another benefit of the solution is that it depends on all the necessary files being uploaded and available to a website visitor. If a file isn't uploaded to the server, the automation script doesn't create a database entry. Without the database entry, the website can't display a broken link. Having the link not appear can be an easier way to tell that a file is missing versus needing to click on every link to make sure all the files are there.
0 Comments
There are currently no comments.
Leave a Comment